Joining data
A Bristol Herald Courier case study
Bringing two data sets together might be one of the most important processes in a data journalist’s tool kit.
Joining data can reveal patterns and provide meaningful insight.
It takes creative thinking to come up with a data set to compare another to.
It takes additional skill to prepare the two data sets to join successfully.
Joining data is a tough process and an even tougher concept to process at first.

But when you’re successful, it’s one of the most satisfying feelings ever.
Case study
We’ll be learning how to join data by replicating part of the data analysis process used in the Pulitzer-award winning investigative series from the Bristol Herald Courier by reporter Daniel Gilbert.
Case study
One reporter at a small local newspaper was able to dig into a story that had a large impact on its readers, revealing mismanagement of natural-gas royalties owed to thousands of land owners in southwest Virginia, spurring state lawmaker action.
It's all about oil
It comes down to royalties for leasing mineral rights to oil and gas companies.

Who owns it?
It used to be that whoever owned the land where the well was owned all the rights to the oil, no matter where the oil technically was.
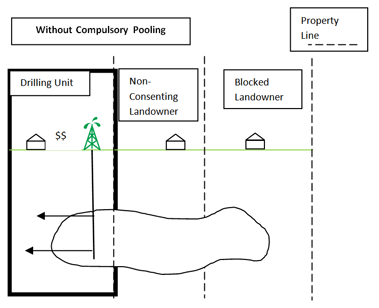
That inevitably lead to some hard feelings
That lead to the idea of “compulsory pooling”
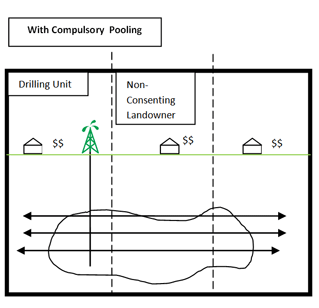
The Virginia Gas and Oil Act
Passed in 1990 as way to develop the state’s coalbed methane without having to deal with who actually owns the land it came from. A form of Eminent Domain called force pooling allowed gas companies to pull the gas on land they didn’t have permission of.
If they couldn’t find out who land owners or the property was under dispute, the royalties were put in a state escrow.
The reporter attended a hearing of the Virginia Gas and Oil Board and met landowners who were incensed that corporations were draining their gas against their will and not paying them for the intrusion.
It wasn’t a new issue.
“Two prior managing editors had spiked the story,” he recalled. “Royalties, methane gas, escrow accounts– it’s not the sexiest story.”
The story minus the data
With these facts alone, he could have written a stellar story giving voice to citizens’ complaints, and shining a light on a little-known regulatory agency.
That, in many newsrooms, would have been plenty for a “he said/she said” story.
But Gilbert wanted to use data to dig deeper to determine the scope of the issue.
The question
Are landowners not getting paid for gas extracted from wells on their land?
What data exists that could be used to answer?
- Whenever a well produced natural gas, the energy company was supposed to make a monthly payment into a corresponding escrow account.
- Companies report monthly gas production numbers to the state for an online database. The escrow account is maintained by Wachovia Bank, which reports monthly statements to the Division of Gas and Oil.
Solution
Match the production records with the payment schedules to see who had– and had not– been paid.
A reporter's process
After FOIAing the data, Gilbert received spreadsheets with thousands of rows.
He started with one month’s worth of data. He looked in one spreadsheet for a well and then looked in another to see if that well existed in the other.
One by one.
Control+F
Control+F
Control+F
At this rate it was going to take months. He convinced his editor to send him to an IRE data bootcamp to learn how to do it more efficiently.
This required 1) cleaning the data so it could successfully join and 2) joining the data.
Often the data was off by a single white space, by a hyphen, or by a combination of letters.
A reporter's process
Gilbert spent weeks making sure the names of the gas wells on the escrow statement matched the well names on the production report.
He started with one month’s worth of data. He looked in one spreadsheet for a well and then looked in another to see if that well existed in the other.
One by one.
Control+F
Control+F
Control+F
He was combining and comparing the data to answer for the following goal:
Reveal the accounts that correspond to where oil or gas has been produced, but royalties have not been paid.
It took him weeks to clean and compare years of data. But we’re just going to look at one month.
But first…
Explaining joins
joins work when the joints are lined up perfectly.
Sometimes, there are gaps in the join– and that’s OK!

In R, this would be the equivalent of left_join() in R with the dplyr package.
The black canvas would be NA rows and the sand that doesn’t match would just exist anymore.
If you did full_join() with R instead, the leftover sand would be appended to the bottom of the data frame.
There are a whole bunch of other types of joins that we won’t get into now, but you can look them up if you want.
Replicating the process in R
Download the January 2009 Escrow Agent Summary Excel file and save it to your R working directory.

Replicating the process in R
Download the January 2009 Monthly Gas Production file.
(Click export to Excel-- save to your R working directory)
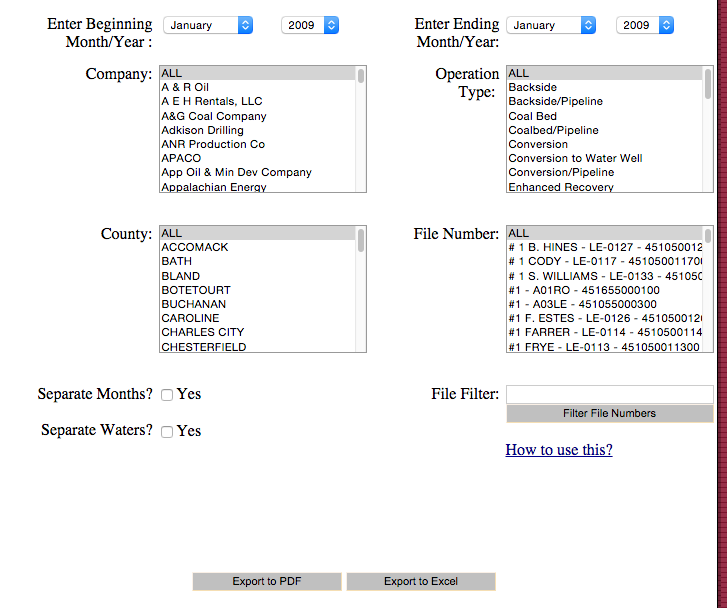
IMPORTANT
It will download a file called ‘frmPrint.aspx’ – find it on your computer and rename it to ‘well_production.xls’
We’re going to use the readxl package to handle importing Excel files and the dplyr package for joining.
library(readxl)
library(dplyr)
library(knitr)
# Importing the data
pay <- read_excel("data/1_January 09_Wachovia.xls")
prod <- read_excel("data/well_production.xls")
Dirty data
Data rarely comes in pristine format. For example, in the second data set, there are no column names.
Those appear in the first row instead.
# prod's column names are in row 1, so fix it
colnames(prod) <- prod[1,]
# now delete the first row of prod
prod <- prod[-1,]
# Let's get rid of any other NAs in the data frame
prod <- filter(prod, !is.na(County))
# After row 734 in pay, the rest of the data is summary. We don't need that.
# This say keeps the pay dataframe specifically from rows 1 through 734
pay <- pay[1:734,]
Prepare the columns to join
Which column do we want to join at?
It appears the “Unit ID” column in pay and “Operation Name” in prod are the well IDs we want to match.
However, you can see that there’s an extra “-” in the prod version.
Prepare the columns to join
We need to strip out any special characters such as dashes and spaces so that we’re just left with the letters and the numbers.
That will ensure better-quality matches.
# First, we need to prep the data we want to join
# Take out the special characters so all we're left with are the letters and numbers
# gsub() is pretty much look for "pattern" with "something else" within dataframe$column
# We'll use regex "[[:punct:]]" and create a new column in each data frame called join
prod$join <- gsub("[[:punct:]]", "", prod$`Operation Name`)
pay$join <- gsub("[[:punct:]]", "", pay$`Unit ID`)
We’ve created a new column called join in each data frame.
This is the glue.
Let’s make the pay dataframe the canvas and the sand will be the production dataframe. We’ll use the left_join() function from dplyr
# Let's join with pay as the basis dataframe
# And select just a handful of columns we care about
pay_check <- left_join(pay, prod) %>%
select(`Unit ID`, Operator, Income, join, Production)
Alright, some success.
There are about 734 wells listed in the pay data set.
You can see in the blank rows (like from 2-10) that the rows on the right half are blank. That means there wasn’t any data in prod that matched the join data.
Let’s narrow it down further on just the data that successfully joined.
# Let's focus on the ones that successfully joined
pay_check <- filter(pay_check, !is.na(Production))
That’s interesting.
Based on a month of data with cursory cleaning of columns, we see that there were 156 wells that produced oil.
But if you look in the income column, a good number of wells received $0.
How many?
pay_check %>%
filter(Income==0) %>%
summarize(Total=n())
That means 24 percent of the wells on peoples’ property listed as producing oil did not get the money they should have in January of 2009.
That’s in line with what Gilbert’s reporting found– which was that of about 750 active individual accounts in the escrow, between 22 percent and 55 percent received no royalty payments.
And this was just a cursory cleaning of the data.
In an actual investigation, a reporter would make sure there were no instances data didn’t join when it should have.
In summary
The data showed
- State did not monitor gas industry’s compliance
- The Billion-dollar energy conglomerates don’t always make the required payments into the escrow
- Of about 750 active individual accounts in the escrow, between 22 percent and 55 percent received no royalty payments
Further investigative reporting
The story doesn’t end after the data analysis. Gilbert had to talk to sources and officials to figure out the why.
- Lack of staffing
- No audits
- No compliance checks (Gas companies were essentially on the honor system)
Story impact
- Government created a searchable database online for payments
- One landowner’s account originally had $1.56.
- After the story, his account had $44,440
- One month later, energy corporations deposited five times the normal average into the accounts
- Won the Pulitzer Prize for Public Service